
Posted: 2022-06-28
This was my keynote talk for ICCC 2022, delivered on June 29th, 2022.
I’m Allison Parrish. I’m an Assistant Arts Professor at NYU ITP/IMA. I’m a poet and I mostly work with computational techniques.
Today I’m going to be talking about paratexts, and in particular how the concept of the paratext relates to my own practice as a poet and computational creativity researcher. I start by giving a field report of my experiences, but I get a bit more theoretical and opinionated at the end.
So let’s begin.
“Paratext” is a term proposed by French literary theorist Gérard Genette, who elucidated the term primarily in his book Seuils in 1987. This book was translated into English (Genette, Paratexts) with the title Paratexts, but the meaning of the original title in French is “thresholds.” And indeed, paratexts are best explained as those texts that are “on the threshold” of other texts: texts like prefaces, introductions, dedications and epigraphs that present the text and put it into relation with readers and the rest of the world.
The term “paratext” also encompasses those aspects of the text that put it in relation with other texts. We might consider these aspects to be hypertextual in nature, such as footnotes, tables of contents, indices, bibliographies and so forth.
The term also includes aspects of the text that at first might appear intrinsic to it: the name of the author, the title, the date of publication, the list price, etc.
Genette’s main concern in Paratexts was books, as cultural artifacts—and I’ll also primarily discuss books and other standalone literary and creative artifacts in this talk. However, I think we can usefully apply Genette’s framework to all manner of texts, with all manner of physical manifestations, even purely digital texts.
Likewise, while my particular expertise and experience is in computer-generated text, I think that the theory of paratexts can be usefully applied to other kinds of media as well, such as music and visual art. I’ll talk about one example having to do with music in a moment.
The paratext, according to Genette, is “a heterogeneous group of practices and discourses” which he groups together primarily “in the name of a common interest or a convergence of effects” (Genette, Paratexts 2). Paratexts provide a “zone of transition (or transaction)… in the service of a better reception or a more pertinent reading of the text” (Genette, Paratexts 2). Genette notes that the kinds of paratexts and the forms that paratexts take are historically contingent—for example, “in some periods, it was not obligatory to record an author’s name, or even a work’s title” (Genette, Paratexts 8).
Authors deploy paratexts not only to conform to literary conventions, but also for tactical reasons having to do with the text in question. New kinds of texts may require new kinds of paratext.
It would be easy to believe that Genette’s theory of paratext does not apply to computer-generated texts, given the unconventional way that such texts come into existence, and their tenuous relationship with conventional ideas of authorship. What I want to demonstrate today is that computer-generated texts are no less bound up with paratexts than any other form of text. Indeed, Genette says that “a text without a paratext does not exist”: “the sole fact of transcription… brings to the ideality of the text some degree of materialization that has paratextual effects” (Genette, Paratexts 3).
We’ll return to this idea of “material” paratexts later.
One reason that I want to discuss paratexts here, in particular, at this conference on computational creativity, is to point out that computational texts do have paratexts, and that the labor of creating those paratexts has value, even though in many cases it might be seen as “non-technical” work. Holly Melgard, whose “Paratextual Play” workshop inspired and informed this talk, phrased this as an axiom: “paratextual labor is meant to be invisible.” I’m hoping to make that labor a little less invisible today.
Additionally, the keynote talk itself, as a genre, can be understood as a kind of “paratext” of a conference. A keynote talk, like a paratext, is neither “on the interior nor on the exterior” of the conference: “it is both, it is on the threshold” (Genette, Paratexts, xvii). Keynote addresses are not held to the same scientific standards as the other talks in the proceedings, and are often offered by individuals who (like myself) are on the periphery of the conference’s community. Genette writes that it is on “the very site of the threshold” that paratexts must be studied, which makes the threshold of the keynote an appropriate venue for discussion on the topic.
As I’ve become familiar with Genette’s theory of the paratext, I’ve realized that making paratexts is actually a big part of my job, as I suspect it may be for other artists and academics (not just in this field, but in all fields). And a lot of the paratexts that I make are specifically about or for computer-generated texts, and some of those paratexts are themselves computer-generated. I’m going to talk about a handful of these now.
Let’s begin with the blurb. By “blurb” I mean a short text that is used for marketing purposes, often included on the cover or opening pages of a book, and maybe also in press releases and on the book’s website. I am frequently asked to produce blurbs for books. Here are a handful of blurbs that I’ve produced recently specifically for computer-generated books:
For Golem: (Montfort)
“A rewarding expedition on the branching paths that connect grammar and code. While Zach Whalen’s lucid postword attends to the text’s recursive clockwork, Montfort’s Golem invites equal appreciation for its sonorous lexical and syntactic counterpoint.” —Allison Parrish, author/programmer of Compasses and Articulations
For Data Poetry (Piringer):

“Jörg Piringer’s wunderkammer of computational poetics not only showcases his thrilling technical virtuosity, but also demonstrates a canny sensitivity to the material of language: how it looks, sounds, behaves and makes us feel. Piringer’s insightful introduction and commentary serve as guideposts for interpretation, making Data Poetry a collection that invites close reading, and is bound to foster discussions about the aesthetics (and implications) of computer-generated creative writing.” — Allison Parrish, Assistant Arts Professor at NYU ITP/IMA, author of Articulations
For Amor Cringe (Allado-McDowell):

“Allado-McDowell deftly shepherds the machine through a series of fractional subjectivities, producing prose that careens between sacred and vulgar, colloquial and arresting. Amor Cringe is a Bretonesque, bawdy necromancy that will enthrall you and make you laugh.” – Allison Parrish, Assistant Arts Professor, NYU ITP/IMA
The “blurb of the computer-generated work” is itself an interesting genre of writing, worthy I think of an in-depth study (perhaps by an enterprising humanities PhD in this very room today).
I actually enjoy writing blurbs. Being asked to write a blurb is a welcome opportunity to engage with a text in-depth, and writing a blurb is an interesting constrained writing exercise: I’m often asked to write thirty words or less, or two sentences, or to comment on a particular aspect of the text, and so forth.
Looking over the blurbs I’ve written here, I can see that they share some semantic and rhetorical similarities: they all allude to the technical underpinnings of the works (“recursive clockwork” of Golem, Piringer’s programming “virtuosity,” Allado-McDowell’s “shepherd[ing] of the machine”), but also make promises about the aesthetic experience of reading the text. I also link these texts to historical precedents (e.g., comparing Amor Cringe to Breton).
One purpose of the blurb is to contribute a sense of legitimacy to the work. This is a necessity for books of computer-generated text, given that we live in a culture in which computer-generated works are still often subject to having their literary and aesthetic value questioned or dismissed out of hand.
On the topic of legitimacy, I want to talk about Jhave Johnston’s ReRites project, to which I also contributed a paratext. ReRites is a multi-volume work consisting of the results of Jhave’s daily ritual of editing and elaborating on poetry generated by a neural network. The paratext I contributed in this case was not a back-of-cover blurb, but one of several essays that Jhave commissioned and then included in a companion volume to the work. This paratextual volume, according to Jhave, is an “attempt to bridge the credibility gap” and provide a “kind of endorsement” for a “more traditional literary audience” (Heflin 93).
Part of the work of “bridging the credibility gap” for computer-generated literature is to engage in traditional literary activity surrounding the publishing of a book. One example of traditional literary activity is the book release event. Here’s an example of such a book release event—in particular, the book release event for K Allado-McDowell’s Amor Cringe, held in a very hip Greenpoint warehouse a few weeks ago (DM for address).
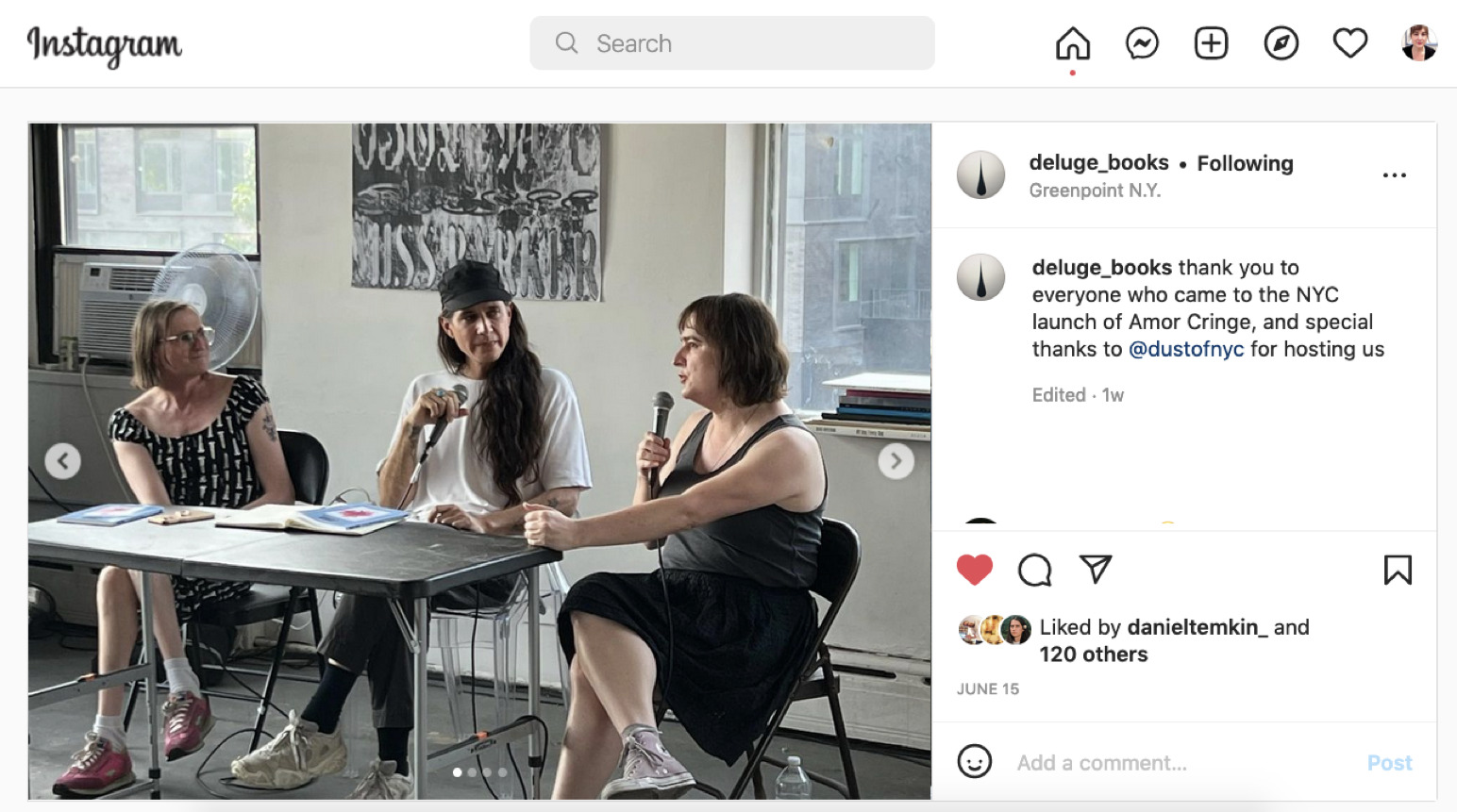
Genette differentiates between two types of paratext: the “peritext,” which is paratext that occurs within the same volume as the text it references, and the “epitext,” which consists of “distanced elements… located outside the book” (Genette, Paratexts 5) that nonetheless help to contextualize the book for its audience. Examples of epitexts include interviews, reviews, private correspondence, letters, diary entries and, nowadays, tweets and social media posts like this one.
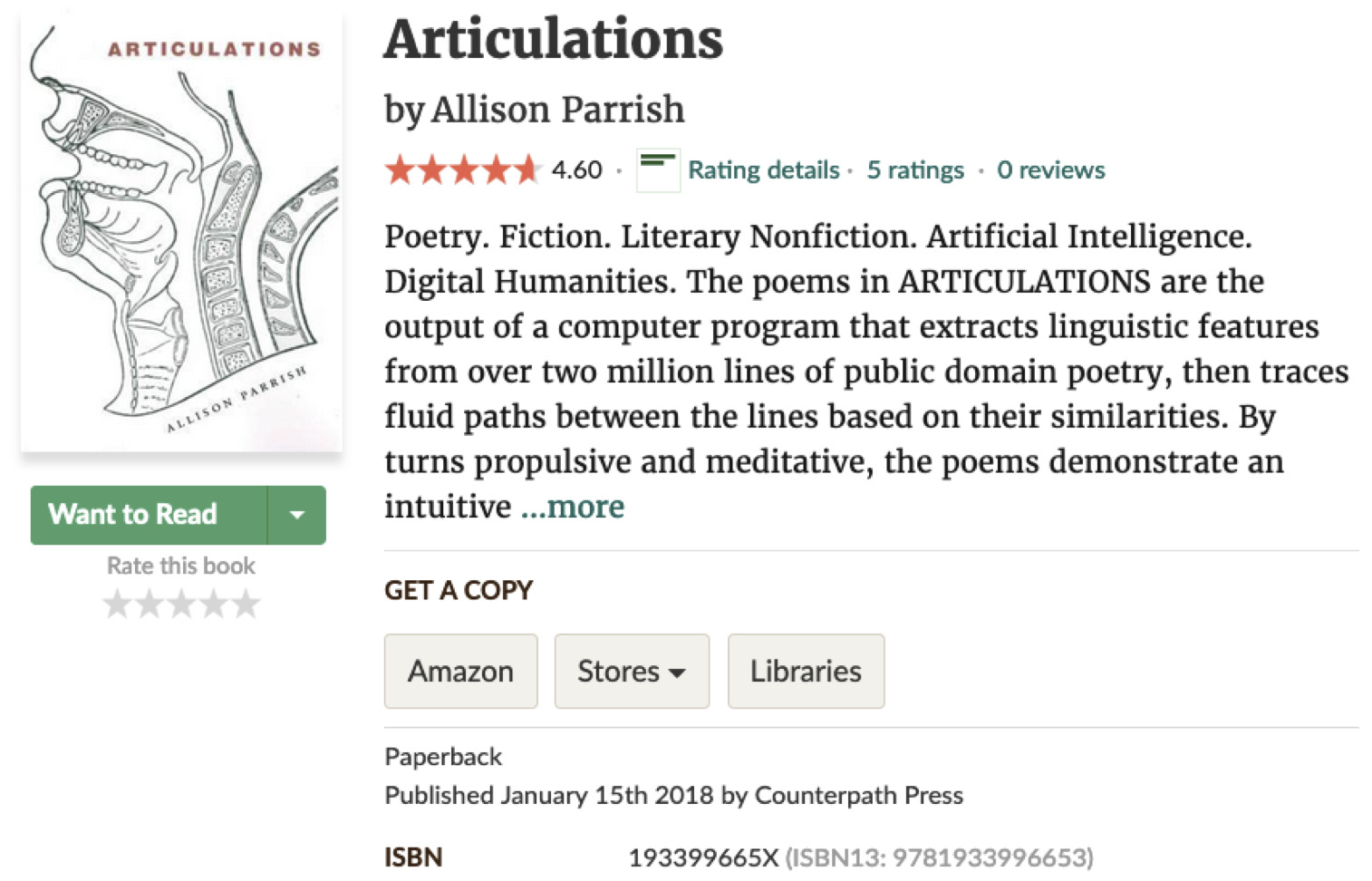
Goodreads is a source of many important epitexts in the Internet age. Goodreads, if you are not aware, is a social media site owned by Amazon where people can show off the books they’re reading and write reviews about them. My book of computer-generated poetry, Articulations, has a respectable rating of 4.6 stars on Goodreads (although the n of 5 is admittedly small).
In addition to posting ratings and reviews, Goodreads allows users to add books to “lists,” and the site displays the names of all of the lists that any given book has been added to. My favorite epitext for any of my books is the one shown below, which indicates that my book has been added to a list called “Self Taught Cave Dwelling Child Poets.”
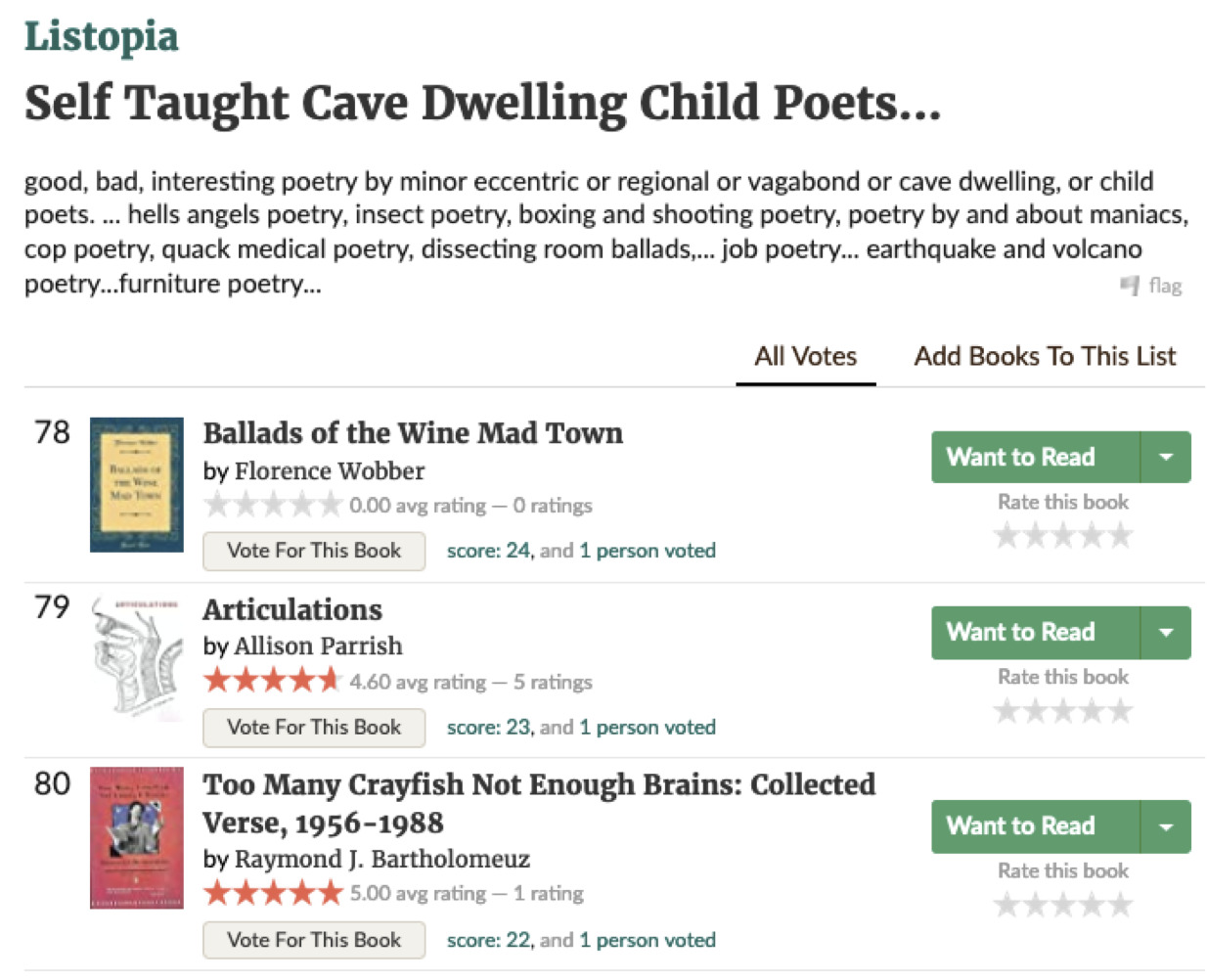
I admit to being a self-taught poet, in the sense that I don’t have an MFA in creative writing or anything like that. However, I live not in a cave but in a Brooklyn brownstone. I am forty years old, but perhaps I am still a child at heart.
I have been commissioned on occasion to write computer-generated paratexts for computer-generated media. This includes writing the introduction for the liner notes for the LP of YACHT’s Chain Tripping (YACHT) which I’ve excerpted below:
Each of these hidden lakes has its own character and therefore its own charm. They show not only a childlike curiosity about the doings of the day and the things that befall people, but a childlike indifference to moral inference and justification. “California Dali / The dreamer is melting.” I do not know that even in this age of charlatanry, I could point to a more barefaced instance of imposture on the simplicity of the public to the public, or very creditable to myself.
I created this introduction by making a small corpus of introductory paratexts (drawn from Project Gutenberg), and then linked together sentences drawn from that corpus using semantic similarity. It was actually in the process of writing this introduction that I first learned about Genette’s theory of the paratext. Thank you to the research librarian at NYU who patiently responded to my question about whether or not there was an existing corpus out there of introductions and prefaces.
I also wrote a series of prose poems to accompany the GAN-generated images in Casey Reas’ Compressed Cinema, an art book forthcoming from Anteism. These poems are intended to serve both as a kind of introductory text for the book, and also as captions for the images, and so I consider them to be a kind of threshold (or paratext) to the images themselves. My method for creating these texts was to attempt to conceptually invert the process of generating an image from a GAN. To that end, I composed (by hand) one-sentence descriptions of each spread of GAN images in the book, and then used Facebook’s BART to iteratively expand these descriptions. As an example, here is one of the original GAN image spreads:

Here is my original ekphrastic description of this image:
The paint’s buckled: a shoulder’s thermocline, an elbow’s tentfold crook. Night, sheared off, drools a golden geode, then waltzes.
And here is the text, after having been “expanded” by BART:
The paint’s peeled away and the canvas has buckled: a shoulder’s exposed, a hand’s wrapped in a towel, a face’s tucked under a pillow, a head’s half hidden by an arm, a chest’s hidden behind a thermocline, an elbow’s tent fold over a crook. Night, sheared off, from the sky. The moon drools a golden tinge from the mouth of the cactus that lies in its mouth, then a yellow tinged from the top of the blackened geode, then waltzes.
My own descriptions were intentionally laconic, dense and ambiguous, to reflect the properties of the images that seemed most salient to me. The language model serves to “decompress” these descriptions, rendering the language more conventional.
In retrospect, the specific challenge of producing a computer-generated paratext is to make the paratext serve both its typical, Genette-esque function of relating the text to the world, while still serving and fitting in with the aesthetic and rhetorical goals of the work in question. That is, a computer-generated introduction should not only play the “game” of the computer-generated work, but it should also manage to successfully provide a way into the work in question. I’m not sure I succeeded in either of these cases, but I tried my best!
I also write paratexts for my own work, and depending on the project, writing these paratexts can be almost as labor-intensive as the process of producing the work itself. For example, my publisher asked me to write the descriptive copy for the back cover of my book Articulations. This was my first book of poetry, and I didn’t know that it was conventional for the poet to write their own copy for this purpose. The process… took forever, and I’m not totally satisfied with the result:
The poems in Articulations are the output of a computer program that extracts linguistic features from over two million lines of public domain poetry, then traces fluid paths between the lines based on their similarities. By turns propulsive and meditative, the poems demonstrate an intuitive coherence found outside the bounds of intentional semantic constraints. (Parrish, Articulations, back cover)
It’s a bit bombastic and I’m not at all sure about the word “propulsive.” Sounds more like I was writing marketing copy for a motorboat than a book of poems. But what’s done is done!
But the most time-consuming paratext to compose is the introduction. I feel that it’s necessary to write an introduction for pretty much all of my books and poems, and in some cases the introduction can spin off into an accompanying essay that is longer than the original piece. I don’t mind doing this work, since I think it’s important to give the reader a bit of information about what’s happening in the work, and what the stakes are from an aesthetic and conceptual standpoint. I also think it’s important to let the reader know what phenomenological effects they can expect while reading. As we’ve seen with ReRites, it seems like creators of computational works feel unusual pressure to give their works an outer layer of contextualizing information, in order to catalyze more favorable readings. But it’s my belief that this kind of context can only enhance the reading experience, and I wish that more poetry—computer-generated or not—included material like this.
A question is whether this bit of contextualizing paratext should in fact be an introduction, or if instead it should occur at the end of the text, as an “author’s note” or “afterword,” or even a “notanda,” to borrow from Zong! (Philip and Boateng). I teach a class on computer-generated poetry at NYU, and this is a perennial topic for discussion among my students. Both approaches have benefits and drawbacks. An introduction gives the reader more tools for interpreting the text up front, but it may foreclose on the possibility of unexpected readings. An afterword, on the other hand, demonstrates trust in the reader’s literacy skills and interest in the text. I’ve tried it both ways—Articulations has an introduction, while my zine Compasses has an afterword.
A work of mine that has especially complex paratexts is Wendit Tnce Inf (Parrish, Wendit Tnce Inf), recently released on James Ryan’s Aleator Press. This is an asemic work, in which a suite of GANs I trained on images of English words feeds into a second program I wrote, which arranges the resulting images in a format resembling conventional book layout. At first, James and I wanted to preserve the integrity of the generated artifact by including no conventional peritext whatsoever in the printed artifact. We toyed with the idea of including a separate insert with this information instead. In the end, though, we opted to include my afterword and a publisher’s colophon both in the body of the book itself. This was primarily to save on the labor and material costs of printing a second booklet. I think it worked fine, though!

The program I wrote that performs the layout in Wendit Tnce Inf has two main steps: create the chapter headings, then create full-justified paragraphs—these are what Genette would think of as the non-paratextual elements of the book. But the program also produces two notable bits of paratext: first, the title page, and then this page, which is intended to look like a dedication.


What’s interesting to me here is that the title page does actually do paratextual work—the title of the book does indeed result from the wordforms generated by the GAN on that page, as interpreted by an OCR algorithm. I’m less certain about the dedication page. Is the book actually dedicated by this text (if indeed we can call this “text”)? I’m just a poet so the question is above my pay grade and I will again leave it to the humanists to puzzle this one out.
I think my favorite paratext that I’ve worked on is the very brief introductory text that accompanies my pamphlet 200 (of 10,000) Apotropaic Variations, published by Bad Quarto (Parrish, 10,000 Apotropaic Variations). The work itself is composed of nonsense words generated from a neural network that I trained on spellings and pronunciations from the CMU Pronouncing Dictionary (Carnegie Mellon Speech Group). The nonsense words are created by inserting random noise into the model’s hidden states during the inference phase, which results in phonetic and orthographic variations on any given input word. Each of the pamphlets has two hundred unique variations on the word “abracadabra”—a magic word traditionally used to ward off evil.
 I co-wrote the pamphlet introduction with Nick Montfort. The text reads in full:
I co-wrote the pamphlet introduction with Nick Montfort. The text reads in full:
Each word inside wards off harm in a unique way. Speaking a word aloud will offer some aid. For real protection, however, you should cut the word out from this sheet and wear it on your person or ingest it.
Usually “directions” and “indications” are paratexts reserved for the labels of over-the-counter medications. I was pleased here to be able to incorporate these kinds of paratexts into a literary work.
Another bit of paratext that I want to discuss is the attribution of authorship, which is certainly one of the most salient and contested bits of paratext when it comes to computer-generated text. It’s often the case that people who create texts with unusual systems and procedures attribute authorship to the system that generated them. A notable example is Racter, the program that William Chamberlain and Warner Books attributed with authorship for the book The Policeman’s Beard is Half-Constructed (Chamberlain). But we can find even earlier examples of this phenomenon, including Christopher Strachey’s attribution of his 1954 computational love letters to “M.U.C.,” the “Manchester University Computer” (Sample), and the 1853 attribution of a novel called Juanita to a talking chair (Enns).

Leah Henrickson has argued that the “hermeneutic contract” leads readers to demand unambiguous authorship in literary works, and that this demand is so strong that machines become “social agents” themselves that can usefully be attributed with authorship (Henrickson 56). But as Henrickson herself points out, quoting Foucault, “the author does not precede the works.” The attribution of authorship is in fact a fundamentally social and paratextual act that serves to “streamline processes of meaning-making,” obscuring “the subjective nature of reading” and “contributing to a sense that a text has a ‘correct’ interpretation rather than full appreciation of that text’s contextual malleability” (Henrickson 51).
In other words, the designation of author is in no instances actually achieved by the machine itself, but instead by human actors hoping to position the text for certain kinds of reading. For my part, I am very careful to attribute the authorship of my works to myself, since I made them, and I want to take credit for their virtues, and I recognize that I am ultimately responsible for their faults. I also don’t believe that the networks of collaboration and intertextuality that go into making a computer-generated text are any more or less rich than the networks for text that is written conventionally. I demand for myself the same privileges of authorship that conventional writers enjoy.
I hope I’ve shown here how paratextual labor is woven through the work of making computer-generated literature, at least in my own practice. Sometimes my work evolves along with its paratext. Sometimes the work is itself the paratext. Attending to this aspect of literature is a way of investigating and performing what Genette calls “transtextuality”—that is, “textual transcendence… everything that brings [the text] into relation (manifest or hidden) with other texts.” Transtextuality includes paratexts as a subcategory, but also other forms of textual inclusion, like quotation, and all aspects of the text that link it to “the various types of discourse it belongs to… thematic, modal, formal” and so forth (Genette, The architext 81).
Genette wrote that “the work is never reducible to its immanent object because its being is inseparable from its action” (Genette, Paratexts, xvii). Attending to transtextuality is important for this reason: it’s the lens through which we understand not just a text’s “meaning” (narrowly construed), but a text’s effect on the world—aesthetically, materially, politically.
In The Architext, Gennete suggests that any system of classification affords “extrapolation” from empirical observations—that the existence of an “empty compartment” in any taxonomy can help you to “discover a genre… otherwise condemned to invisibility” (Genette, The architext 66). Therefore, if you’ll allow me, I propose that the existence of transtextuality implies the existence of its opposite, cistextuality. (Cis- here is the Latin prefix for “on the same side of”, as opposed to trans-, meaning “on the opposite side of.”) If transtextuality consists of an appreciation for how a text always overflows into the world that surrounds it, and cannot always be cleanly separated from it, then “cistextuality” is an insistence that, to the contrary, text is something can and does stand alone.
Now, to some extent, the purpose of a conference like this one is transtextual in nature. Many of the papers on offer here fall into a category that Genette would call “public authorial epitext” (Genette, Paratexts 352). In particular, I think the academic paper that concerns a creative artifact, or a system for producing creative artifacts, is a species of “autoreview” in which the authors publish a review of their own work. This form of paratext is rare in the literary world, but very common (if not obligatory) in the world of computational creativity.
Still, there are a handful of trends in this field, and the related fields of computational linguistics and natural language processing, that I’d like to name as being fundamentally cistextual in nature. Again, my discussion here is primarily about literature and other forms of creative text, but I hope that those of you working in other media will be able to usefully extend this framework to think about your own work.
To discuss cistextuality in more detail, however, I need to begin with a little detour on hermeneutics—that is, the ways in which readers interpret texts. A common folk theory of hermeneutics is that reading is a simple process of recovering the meaning “encoded” in a text. This theory states that reading is not just a passive process; it is also a uniform process. That is: there is only one “correct” method to interpret a text, and every text ideally affords only a single interpretation. However, this is not the case!
In fact, reading is “an active, transactional engagement with a text to construct meaning.” What’s more, “reading has a history. It was not always everywhere the same” (Murray 374, quoting Darnton). Every text is therefore born into a contextual, contingent reading environment. Paratexts are one of the ways that authors manage and guide the relationship between a text and these reading practices.
But a text also creates its own reading practices. Authors use paratexts not just to negotiate between two fixed truths—the text and its readers—but to bring into existence a particular set of reading practices that the individual text affords or demands. (This is, in fact, the reason that I have to do so much work on paratexts for my own works, which often require unusual kinds of reading!)
What I’m calling “cistextuality” is an insistence that, despite evidence to the contrary, texts are static, that meaning inheres exclusively within the text, and that it’s possible to ascertain meaning from a text without context. The purest manifestation of the cistextual imagination is found in machine learning and natural language processing, where texts are often represented as a one-dimensional array of integers that correspond to token types. This method of representation strips the text from its context and its material format, and sets up a basis for textual “identity,” “similarity” and “semantics” that does not (and cannot) take contextual and material factors into account.
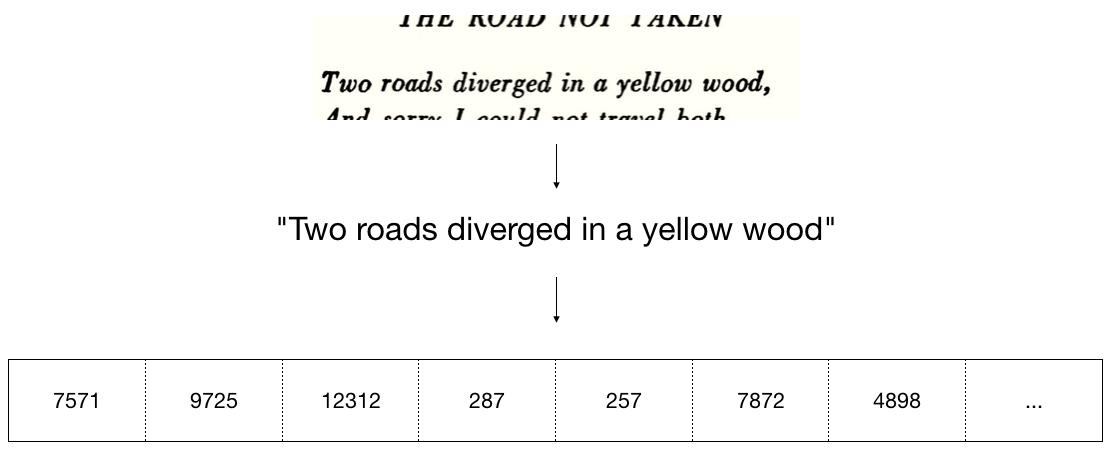
There are consequences for deforming text in this manner—for removing it from space, freezing it in time, and reducing it to a single dimension, like unraveling the weft from the warp in a textile, pick by pick. This method of representing text underlies large pre-trained language models like GPT-3, which are currently among the most visible technologies in the fields of machine learning and natural language processing, both in popular culture and in academia. The shortcomings and harms of large pretrained language models have been thoroughly cataloged elsewhere and I won’t reiterate that discussion here (e.g. Bender et al.), except to say that such models produce “cistextual” text: text that is stripped of its paratextual and transtextual elements, up to and including the names of the original authors of the text.
Here’s another form of cistextuality that I’d like to discuss. In academic papers about text generation systems, there seems to be a convention dictating that no actual textual output from the system itself should be shown in the paper, or at least very little. This convention results in systems that are evaluated not for their ability to make text, but for their ability to create one-dimensional arrays of integers that conform to particular statistical tests. The chart below is drawn from a paper I chose at random from my “text generation” folder in Zotero (Prakash et al.), which itself isn’t a particularly egregious example of the trend I’m discussing, but it makes a useful example. If you go to arXiv and search for “BLEU” you’ll find many other papers that exhibit this same characteristic.
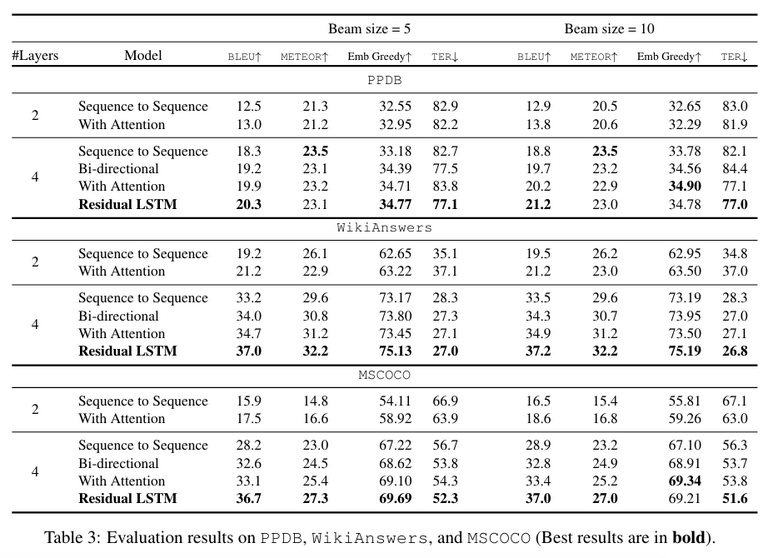
Language generated in this fashion, for these goals, has had nearly all of its “transtextuality” denied. The text’s readership and contextual relationships have been narrowed down to one kind of automated reading. This isn’t even “language to cover a page” in the Vito Acconci sense. It’s “language to improve on a metric.” If “all reading is rooted in the social” (Rehberg Sedo 16), then this kind of text is only social secondarily—“read” only through its statistical properties.
The idea of an author producing a text only for secondary effects calls to mind Marcel Broodthaers’ “Pense-bête,” a volume of poetry books set in plaster. As Craig Dworkin notes, “this work can be the subject of attention (contemplated as sculpture) or of use (opened and read) but not both” (Dworkin 4). Likewise, text generated for academic papers on text generation can be contemplated for their statistical properties, but not actually used (i.e., read).

Even Broodthaers’ book, and our hidden generated text examples, admit to some kind of “textual transcendence.” Text that exists only as sculpture or as statistical scores still has a context of interpretation. In both cases, the interpretation is based entirely on the text’s material form. (As a string of integers in one case, and as a sculpture in the other.)
This brings me, at last, to the title of this talk. Here’s what I mean by “material paratext.”
A text’s material form influences how the text is interpreted—in other words, forms produce meanings. A text’s visual appearance, its tactile attributes, its sounds and its smells all affect its reception, or sometimes even determine it. Even “purely” digital text is “profoundly material” (Murray 387) when you consider the infrastructure that makes it possible (electronics factories, data centers, undersea cables, etc.).
Moreover, a page—whether on the screen or on dead plant matter—is multi-dimensional, and therefore subject to organization in space and in time. Even texts that don’t draw attention to their material form still condition physical action. The saccade of eye movement across the page, the necessity of turning the page, scrolling through a text on the screen, turning back and forth from endnotes or the table of contents—these are all actions that take time and energy. This holds true even when we consider wholly automated forms of reading: machine learning models are well known for the catastrophic amount of energy that they consume during their “reading” of a text.
To the extent that writers, authors and other creators of texts use material format as a means to contextualize language, we might consider a text’s material form to constitute a “material paratext.” Ignoring or minimizing the importance of material paratext is yet another way that I’ve seen cistextuality manifest itself in the fields surrounding machine learning and natural language processing.
I would contend that the term “material form” can usefully be extended to include not just the material form of a text’s presentation, but also the material decisions that went into its creation. As linguists Silverstein and Urban note, “The text-artifact does indeed have a physical-temporal structure, precisely because it was originally laid down, or sedimented, in the course of a social process, unfolding in real time” (Silverstein and Urban 5). I would paraphrase this as: formations produce meanings.
This is true of computer-generated texts as well. For sure, there is often a complicated relationship between the form of a computer-generated text and the real time processes that conditioned it, but the process of creating a computer-generated text is still profoundly material. Computer-generated texts result from material decisions made with material objects in material environments. For a typical text generation project, these decisions might include: the hardware that the model was trained on; the labor that went into producing the corpus that the model draws from; the act of typing in the source code; the brand of air conditioner installed in the grad students’ office, etc.
Readers routinely reconstruct the material basis of a text’s composition while interpreting a text, whether computer-generated or not. Creators of computer-generated texts have various ways of communicating these material circumstances to their texts’ readers—in particular, the kinds of paratexts that I mentioned earlier, like academic papers and afterwords.
With all this in mind, I’ve been making an attempt in my recent work to pay close attention to material paratexts. As a concrete example, I’m going to talk briefly about my solar-powered dawn poetry project. This project, whose initial stages were undertaken as part of a residency with CultureHub, consists of a radically small language model (a Markov chain, in fact), trained on a low-power microcontroller, which operates only when drawing sufficient energy from solar panels. The language model is trained on a corpus of albas or aubades, a genre of poetry genre in which lovers lament the oncoming dawn. The system generates new examples of poems in this genre—again, using only solar power.

The bill of materials for the system is less than US$60, and it runs purely on solar power: no batteries or wall wart required. The system on average draws about one eighth of a watt—about 0.04% of the power usage of a typical GPU. The corpus is composed entirely of works that are in the public domain in the United States, many of which I’ve had to manually transcribe from rare physical books or recover from poorly indexed scanned books that are behind the library paywall. My plan is to release the schematics, source code, and corpus for re-use by others, under open source and creative commons licenses as appropriate.
My goal for the project is to demonstrate what it’s like to really think through the material paratext of computer-generated text. What does it look like when you have to account for every watt of power you use, instead of feeding fossil fuels and dollar bills into the “cloud”? What does it look like when you have to account for every word in your corpus, instead of blithely chewing through terabytes of words that you stole from the Internet? What can be gained from this kind of care?
Because I still need to optimize my code a bit, this poetry generator has so far only generated these eight lines of poetry:
For rage to be numbered,
And whilst love mounts her on earth.
Still wander, weeping, wishing for the fair,
Lest the cock crow reveillie,
Thou too, Phoebus,
Wake up! wake up!
as if shedding on me a light that sorowe
So thou wilt have it so.
It’s not much, but I’m satisfied that the interpretation of these lines, and the value that readers assign to them, has a solid foundation to fall back on—namely, the material paratext.
We’ve seen how computer-generated texts are often assigned “cistextual” at birth, through a denial on the part of the text’s creators to connect the text to its context and to the world. The thought I’d like to leave you with this morning is this: no matter how hard you try, forcing a text to be cis always fails. A text is always transcendent. As Genette wrote, “a text without a paratext does not exist,” and this is true of material paratexts as well. You can’t erase a text’s material history, no matter how much linear algebra you do to it.
I’d like to acknowledge Leah Henrickson for her book Reading Computer-Generated Texts, a thorough and well-argued book that I nevertheless profoundly disagree with. Dr. Henrickson’s book provoked a lot of the thinking that went into this talk and also provided a useful bibliographical trail for me to follow.
I’d also like to thank Holly Melgard for her recent workshop at Ugly Duckling Presse called “Paratextual Play.” This workshop spurred me to pursue the lines of thinking in this talk and also provided a firm theoretical and historical foundation for me to build on.