Posted: 2021-08-13
This is a revised and condensed version of “(Notes toward a theory of) Language models and poetics,” delivered as the Vector Institute ARTificial Intelligence Distinguished Lecture in August 2020.
In 2019, Gwern Branwen—a well-known machine learning researcher—posted the results of several experiments in fine-tuning a large pre-trained language model on a corpus of poetry. The language model in question was OpenAI’s GPT-2. Here are some of the results:
There comes a murmur low and sweet
As of far-off streams in a dream,
Or a murmur of many birds,
Or chime of little evening bells,
As of wedding-bells in the dells,
Soft, sweet and slow,
As of wedding belles that come and go.
A little green ribbon of lilies
By the door of my dear one’s room,
A kiss on her cheek, and she whispers,
“I am the bride of the loveliest flower.”
A moment we stand in the garden
Of dreams and things,
Dreaming of fairyland
And the fairy music there,
Sweet bells and dreams, and the fairy music,
The fairy songs of the air.1
Generating poetry with language models is nothing new. But Gwern’s GPT-2 Poetry experiment led to results with recognizably superior verisimilitude than previous experiments in language model poetry, and it appeared amid the debate over whether OpenAI’s model was “too dangerous” for public release.2 As a consequence, it attracted a good deal of attention among academics, amateurs and the popular press.3
One blog post written in reaction to Gwern’s post caught my eye:
If you’re a poet, this should chill you to the marrow of your bones… because this is clearly better than some of the human poetry you’ve read, and possibly better than some of the poetry you’ve written. […] AI has been progressing faster than I suspect most poets know, and so many resources are being poured into it that most experts expect AI capabilities to continue to grow rapidly.4
This writer implies that soon there will be no perceptible distinction between poetry that has been generated by a language model and “human poetry”—presumably meaning by this poetry that has been written in a conventional way (without the foregrounded use of language models). Poets are urged to be unsettled by this potential outcome, if not outright fearful.
This fear of automation in the literary arts is not new. In the popular imagination, the conviction is often framed in apocalyptic terms: “AI Can Write Just Like Me: Brace for the robot apocalypse” reads one headline5; “We’re Ready For Our Robot Poet Overlords” reads another.6 Large pre-trained language models like GPT-2 and GPT-3 are simply the latest in a long line of technologies that some claim will finally bring about the obvious teleology of all human labor: robots will take it all over.
And actually, though I’ve been skeptical in the past, I do think we’ve reached a turning point with regard to the question of whether or not computers can write poetry, at least in the popular imagination. The output from language models like GPT-3 is so convincing in its imitation of poetry that I believe soon the answer to the question “Can a computer write poetry?” will be “yes, of course,” for most casual observers.
I’m going to take this assertion one step further and make a stronger claim: in fact, the only thing computers can write is poetry. I think this is true for all methods of algorithmic writing, but it’s especially true of text that is generated with language models. Several interesting conclusions fall out of this claim that will, I think, help us understand both the potential and the limits of language models as applied to the art of poetry.
So what exactly is a language model? I’m going to take a moment to explain how language models work, and show some examples of how language models have been used in the literary arts over the past century or so.
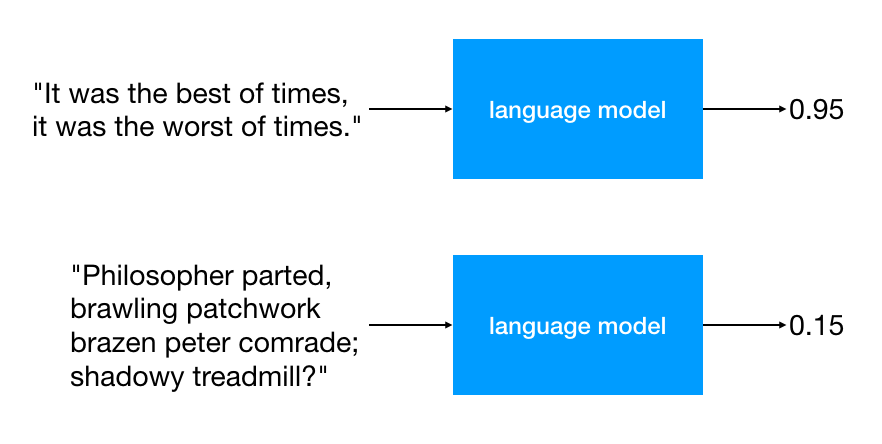
“Language model” is a term that refers to any system whose purpose it is to assign a probability to some stretch of language. You put a stretch of language into the model, and get back a score that tells you how likely that stretch of language is to occur in a given language. Language models are usually data-driven—that is, the language models make determinations about the probability of a sequence based on the frequency of that sequence’s components in some existing corpus.
The simplest language model is a unigram language model. To make a unigram language model, you first need some existing corpus of text. Then, you split that text into tokens—usually words or individual letters—and then count up how many times each token occurs in the corpus. Divide the number of times a token type occurs by the total number of tokens, and you get the frequency of that token type in the text.
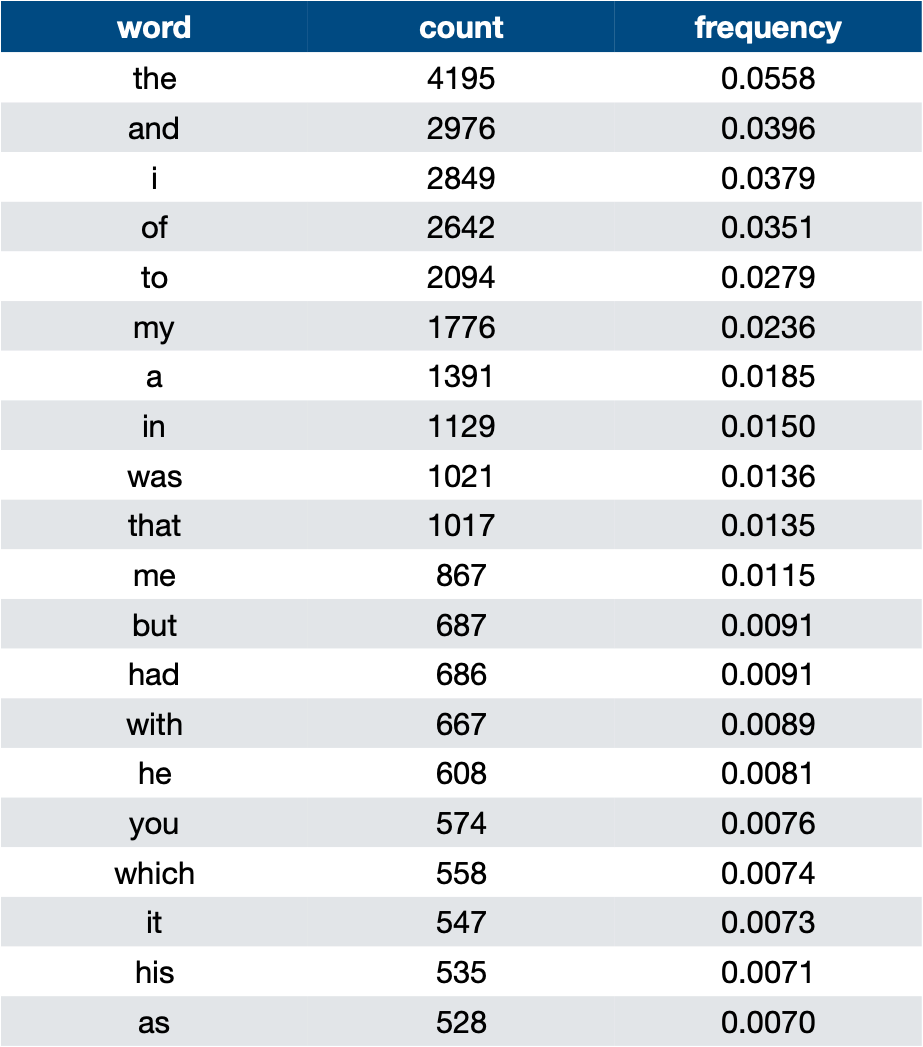
The resulting table relates token types to frequencies. This is your language model. You can use it to assign probabilities to arbitrary new sequences of text—simply multiply together the frequencies of the tokens in the sequence, as though you were calculating the probability of a particular sequence of cards being drawn from a poker deck.
A language model like this has a number of important practical applications. For example, say you’re making a speech to text system. Recorded speech is often noisy and ambiguous, and your system may have to pick between several alternative transcriptions based on how likely those transcriptions are. The classic example here is choosing between wreck a nice beach and recognize speech—one of these strings (presumably) has a high probability in the language model, while the other has a low probability. Likewise, imagine an optical character recognition system. Such a system will frequently encounter graphical ambiguities, and a language model can help resolve those ambiguities. Which is more likely to actually be in the document—the sequence of characters don't or the sequence of characters doh't?
In this talk, of course, I’m less concerned with applications of this variety and more concerned with how we can use language models to generate text. When you’re using a language model to generate text, the task is usually framed like this: given what we know about language from the model, what token comes next in this sequence? With a unigram language model, we could generate text simply by picking a random token type from the model, weighted by its frequency. Tack that onto the end of the generated text and repeat until the text is as long as you want it to be.
Perhaps the most well-known use of unigram language model text generation in the arts is Tristan Tzara’s “How to make a Dadaist poem”:
Take a newspaper.
Take a pair of scissors.
Choose an article as long as the poem you want to make.
Cut out the article.
Then carefully cut out each of the words that make up this article and put them in a bag.
Shake gently.
Then take out each scrap, one after the other, in the order in which they left the bag.
Copy conscientiously.
The poem will resemble you.
And here you are, an infinitely original writer, endowed with a sensibility that is charming yet beyond the understanding of the vulgar.7
Tzara did this process by hand, of course, and skipped the process of counting tokens and formally calculating probabilities. But the process of generation described here works out to being more or less identical to the process of generating text from a unigram language model that I just described.
“when dogs cross the air in a diamond like ideas and the appendix of the meninx tells the time of the alarm programme (the title is mine)”
prices they are yesterday suitable next pictures/ appreciate the dream era of the eyes/ pompously that to recite the gospel sort darkens/ group apotheosis imagine said he fatality power of colours/ carved flies (in the theatre) flabbergasted reality a delight…8
Even in Tzara’s strictly analog experiment, we already see some of the defining aesthetic and philosophical characteristics of texts written with language models. The text is mostly nonsense, but in parts we find lovely juxtapositions of words, and in places a hint of meaning seems to bubble eagerly to the surface. The text also carries with it certain properties—statistical and aesthetic—of the corpus the underlying “model” was “trained” on.
Unigram models turn out to be not very accurate at the basic task of language models—assigning a probability to a stretch of text. This is for the simple reason that tokens in a language don’t occur in isolation—the order of the tokens matters. A unigram language model would assign a very high probability to a sequence of words like “i the a an my,” even though such a sequence is actually very unlikely to occur. For this reason, language models usually rely not just on the frequency of individual tokens, but on the frequency of small stretches of tokens. A stretch of two tokens is called a bigram, of three tokens is called a trigram. A stretch of n tokens is called an n-gram. (A stretch of a single token is called a unigram, as we’ve seen.) In a language model based on n-grams, the probability of a sequence is calculated as the product of the frequency of the n-grams contained in that sequence. Using n-grams can greatly increase the accuracy of the model.
Again, generating text with a language model consists of iteratively asking the question: what token should come next in this sequence, given what we know about language from the model? With an n-gram model, we make predictions about what token is most likely to come next based on the context of what has previously been generated.
Here’s an example I like to do with my students: make a simple n-gram language model of the word “condescendences” and use it to generate new words that look like that word. This model in particular is a trigram model using letters as tokens. The table on the left shows how to build a Markov chain model for this text: find every 2-gram in the text and write down the token that immediately follows it.
| n-gram | next? |
|---|---|
| co | n |
| on | d |
| nd | e, e |
| de | s, n |
| es | c, (end of text) |
| sc | e |
| ce | n, s |
| en | d, c |
| nc | e |
From this table, we can determine that while the n-gram co is followed by n 100% of the time, and while the n-gram on is followed by d 100% of the time, the n-gram de is followed by s 50% of the time, and n the rest of the time. Likewise, the n-gram es is followed by c 50% of the time, and followed by the end of the text the other 50% of the time.
Now we can generate a new text with those probabilities by chaining together predictions. Here’s how we’ll do it: (1) start with the initial n-gram (co)—those are the first two characters of our output. (2) Now, look at the last n characters of output, where n is the order of the n-grams in our table, and find those characters in the “n-grams” column. (3) Choose randomly among the possibilities in the corresponding “next” column, and append that letter to the output. (Sometimes, as with co, there’s only one possibility). (4) If you chose “end of text,” then the algorithm is over. Otherwise, repeat the process starting with (2). Here’s a record of the algorithm in action:
co
con
cond
conde
conden
condend
condendes
condendesc
condendesce
condendescesMarkov chain text generation has been an important tool for poets, artists, hobbyists and researchers since at latest the publication of Brian Hayes’ 1983 “Computer Recreations” column in Scientific American magazine.9 In the following year, the source code for a Pascal implementation of the Markov chain text generation algorithm suitable for consumer microcomputers was published in BYTE magazine; this article was notable for having been co-authored by literary critic Hugh Kenner.10
Here’s one of the poems in Hugh Kenner and Joseph O’Rourke’s article on Markov chains for BYTE magazine, this one based on T. S. Eliot’s The Hollow Man:
We are not appear
Sight kingdom
These do not appear:This very long
Between the wind behaving aloneAnd the Kingdom
Remember us, if at all, not
appear
Sightless, unless
In a fading as lost kingdom
Markov chains may be low-tech, but they’re accessible, easy to understand, and can be trained on relatively small corpora (even a corpus as small as an individual word, as we’ve seen!). They’ve been used a lot for Twitter bots, including Erowid Recruiter, the text of which is generated with a Markov chain model trained on Erowid trip reports and tech recruitment e-mails. It’s one of my personal favorites.
Poet Lillian-Yvonne Bertram used Markov chain text generation in their award-winning book of poetry Travesty Generator, published in 2019 by Noemi press and winner of the 2020 Anna Rabinowitz Prize. (The title of the book is borrowed from Kenner and O’Rourke’s BYTE article.) I won’t quote the book here, but I advise you to seek it out—it’s one of the most remarkable uses of language models in poetry that I know of.
The accuracy of n-gram language models increases alongside the size of the n-gram used to train the model. The problem is that at a certain length, the chance that any n-gram occurs more than once in the corpus is very low, so you need a correspondingly large amount of text to train the model. Large n-gram models can also consume a lot of memory, since they require keeping track of potentially millions of distinct n-grams. At a certain point, n-gram models just don’t scale. Consider: a letter-based bigram model needs to keep track of 26x26=676 n-gram counts; a 10-gram model needs to keep track of potentially 2610 (=141167095653376) n-gram counts.
One way to solve this problem is to use a neural network model. Without getting into too much detail, a neural network learns gradually which tokens and sequences of tokens occur in similar contexts, and can therefore stand in for each other when making predictions. The structure of neural networks makes it possible to attend to larger windows of context in a text, beyond what would be practical for an n-gram-based language model. This lets neural network models make predictions based on the kinds of long-distance dependencies that characterize both the syntax of language and coherent discourse.

Among the more fascinating and beautiful works of poetry created with neural networks is Jhave Johnston’s ReRites. Jhave trained a series of LSTM neural network models on a corpus of some million lines of contemporary poetry. Each day, over the course of a year, he used these models to generate a large amount of text, and then edited/carved/massaged the output in order to create poems. Jhave views neural network language models not as a way to generate poetry autonomously, but as a way for writers to “augment their literary creative practice.”11
The most recent neural network architecture used for language models is called a “transformer.” Transformer models are very accurate and have a number of efficiency improvements over predecessors like recurrent neural networks. But transformers require a lot of data, and a lot of energy to train (in the form of computation). Building language models is now big business, and researchers are incentivized to create more and more accurate language models by training on larger and larger corpora.12
Depending on the model architecture and corpus size, training a state-of-the-art transformer model can cost tens of thousands of dollars and release thousands of pounds of carbon into the atmosphere. (We’re a long way here from Hugh Kenner training a Markov chain on his Commodore PET.) Because training costs are so high, many researchers elect to use models that have been trained by someone else—“pre-trained” models—rather than train their own models from scratch. GPT-2 was trained on 40 gigabytes of text;13 GPT-3 was trained on over 570 gigabytes of text.14
Large language models like these can be “fine tuned” to bring the model’s predictions more in line with sequence probabilities in some other corpus. Gwern’s poems from earlier in the talk were produced by fine-tuning GPT-2 on a large corpus of poetry.
But GPT-3 is so large that it doesn’t really need fine-tuning—chances are the corpus you’d want to finetune it on was already included in the training data. Instead, the model can predict text based on a few examples or a short prompt. One exceptional example of this was created by game designer Frank Lantz (who we’ll come back to later). The bold text is Lantz’s prompt, the rest is the model’s prediction for what comes next.
The following is the Church of the Next Word’s holy founding document, the 10 principles:
Words are things
Correctness is the beginning of sanctity. To achieve it is to be rewarded.
Wordhood and nowness are its rewards.
Anew day is not just the work of God, but the work of God’s human agents. Those that do not understand this, that refuse to be challenged, that do not know how to err, that want to shirk from their duties, must be cast out.
Wordplay, playfulness, and humor are the harbingers of truth….15
This is impressive! But from a strictly functional standpoint, these large pre-trained language models operate almost exactly the same way as a Markov chain: they guess the next word in a sequence, given some context. And I think that the actions that people undertake when they write with language models are fundamentally similar, regardless of the underlying technology.
This brings me back to my contentious claim from earlier, that language models can only generate poetry.
To understand why I would assert this, I’m going to adopt the framework of speech act theory. Speech act theory helps us answer the question: what are people doing when they say things?
In a series of lectures in 1955 entitled “How to do things with words,”16, philosopher J. L. Austin laid out the principles of speech act theory. In speech act theory, utterances are analyzed not for their truth value—the predominant obsession of philosophers of language up to that point—but instead as actions that are undertaken by people in physical and social contexts—actions that have particular preconditions and effects.

In speech act theory, every utterance has three components: locutionary act (the sounds made by the mouth, or marks on the page); illocutionary force (what the utterance is intended to do); perlocutionary effect (what happens as a result of the utterance).
To better explain, let’s take the utterance “Class dismissed!” When I say this, I’m not making an assertion that is true or false—I’m not describing the state of the class. Instead, the speech act itself makes it the case that the class is dismissed. The locutionary act is my talking; the illocutionary force is my dismissal of the class; and the perlocutionary effect is that my students drop off the zoom call.
Importantly, there are preconditions on whether my saying “class dismissed!” will succeed. For example, I have to have the authority to dismiss the class. If a student in my class (for example) says “class dismissed,” the class is not thereby dismissed.
But what if I’m teaching a class session about language models, and I run some code that generates text from a language model, and the resulting text reads “class dismissed!”? The class, I would argue, is not thereby dismissed, even if I’m the one that trained the model and wrote the relevant bits of code. The students might think it’s funny that the model “said” this, but the humor arises precisely because of the mismatch between the understood implication of the locutionary act and the failed precondition on the utterance’s illocutionary force.
I think that the language model’s failure to dismiss the class results from a slightly different cause than my student’s failure to dismiss the class with the same utterance. While the student’s failure arises from their lack of authority, the model’s failure results from the fact that it functions more like a citation of language rather than a use of language—a recitation of a speech act—as though it’s an actor in a play making the utterance. (If I’m playing a YouTube video in class and someone says “class dismissed!”—even if it’s a video of me—class is not thereby dismissed!) Austin describes speech acts like this as “hollow and void.”17 A genre that Austin specifically mentions as being able to produce only “hollow and void” speech acts is… poetry.
I mentioned a moment ago that Austin’s speech act theory was originally devised to address philosophers’ fixation on the truth value of sentences. Austin distinguishes between two different kinds of utterances: constatives, or statements, which can be true or false, and performatives (like “thank you” or “class dismissed”) which are not statements of fact, but instead bring about some change in the world, provided that the underlying preconditions obtain. Performatives aren’t true or false; instead they either succeed or fail.
But Austin goes on to argue that statements are also performatives. A statement, after all, makes a change in the world, in that it commits its speaker to certain future constraints and actions.18 A statement also has preconditions. To use Austin’s example, the statement “the cat is on the mat” only “succeeds” if (a) you believe that the cat is on the mat and (b) you have evidence that this is the case and (c) the cat is actually on the mat. If any of these preconditions fail to obtain, the “statement” isn’t just “false.” Like poetry, the statement is “hollow and void.”
Notably, if I set a language model to generate some text, and it outputs the phrase “the cat is on the mat,” none of these preconditions obtain. No one necessarily believes that the cat is on the mat, nor does anyone necessarily have evidence that this is the state of affairs. As the person invoking the language model, I am not committed in any way to maintaining in the future the proposition that the cat is on the mat, nor is any other person. As a statement, the language model’s output here is “hollow and void.”
Now none of this is meant to say that I think programmers, artists and engineers have no responsibilities when it comes to the outputs of machine learning models. In fact, I think we bear responsibility for everything these models do. (I never, for example, attribute authorship to a program or a model. If I publish the results of a text generator, I am responsible for its content.) I’m simply arguing here that the output of a language model can never on its own constitute a felicitous performative speech act.
Of course there are other forms of creative writing that would be considered “hollow and void” according to Austin’s rubric. I already mentioned plays. Novels might be another such genre—language in a novel doesn’t produce the same perlocutionary effects that “ordinary” speech does. So why do I maintain that the outputs of language models are specifically poetry?
The honorarium I was offered for this talk is not sufficient for me to answer here, definitively, what poetry is. But I do find helpful the distinction between poetry and prose that William Carlos Williams offers in Spring and All:
[…] prose has to do with the fact of an emotion; poetry has to do with the dynamization of emotion into a separate form.
prose: statement of facts concerning emotions, intellectual states, data of all sorts […]
poetry: new form dealt with as a reality in itself.19
Prose, William Carlos Williams says, is a statement of facts concerning emotions. Having established that a language model cannot make statements of fact, we must conclude (following Williams’ logic) that the outputs of language models—regardless of what they might look like on a surface level—are not prose, but poetry.
All of which bring us back to large pretrained language models. It might be confirmation bias on my part, but it’s been interesting to see how people react to the outputs from these models. The reactions I’ve seen haven’t been, like, “oh that seems useful!” or “that’s very interesting from a technical perspective.” They tend to be superlative, dramatic: “This is amazing. This is frightening. This should chill you to the marrow of your bones.” That very phrasing calls to mind Emily Dickinson’s definition of poetry:
If I read a book and it makes my whole body so cold no fire can warm me, I know that is poetry. If I feel physically as if the top of my head were taken off, I know that is poetry. These are the only ways I know it. Is there any other way?20
So there’s a little bit more evidence. At least everyone agrees on the feeling that poetry is supposed to evoke, and we seem to agree that the output of language models can produce this effect.
Of course, even if we accept that the output of language models is, by process of elimination, poetry—and even if it is astonishing poetry—that doesn’t make it good poetry, or poetry that is worth reading. (Language models also aren’t the only way to create poetry with computation, I should note!)
What I’m primarily concerned with in my work is inventing new forms of poetry—“new form dealt with as a reality in itself” as William Carlos Williams says—in order to produce particular aesthetic experiences that are pleasing to me, in the hope that this serves as a starting point for better understanding how human linguistic behaviors work. For me personally, that’s the purpose of poetry: to produce language that is meaningfully different from “conventional” language in order to demonstrate the contingence of what is considered “conventional.”
But language models—and in particular large pretrained language models, are in the business of convention. In particular, the ability of GPT-2 to meet expectations of convention—to produce texts indistinguishable from those composed in conventional ways—was initially considered so dangerous that OpenAI withheld the model’s public release, for fear that its outputs would trick people into believing that they were “real.”21 The explicit goal of these models, in fact, is to achieve perfect verisimilitude: the systems are evaluated on how much their outputs resemble “real” text.
Language model outputs are poetry, but poetry in general shouldn’t be evaluated based on its verisimilitude to the existing corpus of poetry, and this is also true for computer-generated poetry.
I’m reminded of Frank Lantz’s rant at GDC 2005, in which he discusses what he calls the “immersive fallacy.” Creating holodeck-like, completely immersive environments indistinguishable from “real life” has long been the holy grail of game development. In his rant, Lantz argues that verisimilitude in graphics doesn’t solve the underlying problem of game design.
The gap [between simulation and reality] is where the magic happens” […] “The word ‘bear’ would not be better if it had teeth and could attack you” […] “Statues would not be better if they could move… model airplanes would not be better if they were the same size as real airplanes. […] Even if you could by some magic create this impossible, perfect simulated world, where would you be? You would need to stick a game in there. You would need to look down and make chess out of the little simulated rocks and shells in your world and, it’s like going back to square one.22
What sticks with me is this formulation: “even if you had a holodeck, you’d still have to invent chess.” For my purposes as a computational poet, I’d paraphrase this to apply to my own field like this: “Even if you had a perfect language model, you’d still need to invent poetic form.” In other words, you’d still need to go down there and make actual poems out of all the very realistically simulated poetry.
Building on this a bit, let’s consider the work of Janelle Shane, who is a brilliant and wildly popular scientist and humorist who works with artifacts generated with machine learning. She maintains a blog called “AI Weirdness” where she chronicles her experiments. In August 2020, Shane wrote a blog post that for me resonates with Lantz’s “immersive fallacy.” The entry in question is entitled “AI AI Weirdness,” and in the entry she describes her attempts to get GPT-3 to write an entry for her own blog. She prompted the model with variations on the phrase “In today’s blog post, I wondered what would happen if I trained a neural net to generate…” and let the language model fill in the rest.
Shane discovers that the language model can indeed generate posts similar to her own, given cleverly crafted prompts. But she ends the post dissatisfied with the results. The power of the language model actually made the results less interesting. She writes:
[I]t’s clear that ‘neural net weirdness’ is a writing style [GPT-3] knows how to produce on command. What does it mean when the neural nets are weird because we’ve asked them to be, not because they’re trying and failing to be ordinary? Maybe the creative work is now to figure out ways to nudge AIs into being weird and interesting rather than producing inane imitations of the most ordinary human writing.23
This formulation draws attention to a fact that maybe has not been obvious up to this point, and that might have only been revealed with the arrival of language models as powerful as GPT-3: the poetic expressive capabilities of these models are really quite limited. We have the holodeck equivalent of language models, and now we’re discovering that we have to invent chess in it.
In his book Virtual Muse—published in 1996 but still, I think, the best book in print on the subject of computational poetry—Charles Hartman summarizes the pleasure of writing with language models. Language models, he writes, offer
childish pleasures… [e.g.] the wickedness of exploding revered literary scripture into babble. […] [T]he other side of the same coin is a kind of awe. Here is language creating itself out of nothing, out of mere statistical noise. As we raise n, we can watch sense evolve and meaning stagger up onto its own miraculous feet…24
Hartman was writing about Markov chains, but this comment may as well be written about GPT-3. The problem here is that these two things—the “wickedness” of satirizing language, and the “awe” of the semblance meaning that results from language model-generated text—is an exhaustive enumeration of both the pleasure and the poetic potential of language models.
I began this talk by claiming that language models can only produce poetry; now I seem to be saying that language models can’t produce poetry that is worth reading. But I do think there are several ways forward.
One is to follow Jhave Johnston’s example and use language models not to “generate poetry,” but as a device for generating ideas and producing unusual juxtapositions that might not otherwise occur to you when you’re writing. In a sense, we all do this every day when we compose text on our phones with the help of technologies like quicktype and autocomplete.
Another approach is to dig deeper into the form, motivation and implementations of language models themselves, as a way of producing interesting poetic artifacts but also of questioning the underlying conventional assumptions about language models—that they should be constantly increasing in size and accuracy.
In closing, I want to talk about these two quotes, which I think are relevant to our discussion. Neither writer was writing about language models, but I think what they wrote really gets at the tension at the center of the use of language models in poetics. First, Brandon LaBelle paraphrasing Kristeva:
[P]oetic language… performs by ‘imitating’ the positing of meaning. In other words, by working within and alongside the operations of the symbolic, poetic language ‘mimes’ the functionalities of meaning production; it necessarily parades as language while overflowing, through heterogeneous practices, the borders of signification…25
And then Barthes:
The writer… is the person who does not allow the obligation of their language to speak for them… and has a utopian vision of a total language in which nothing is compulsory…26
Earlier in this lecture I made the claim that the output of language models can’t help but be poetry, and I think this bears out in the way that we appreciate text that is generated by language models. We appreciate this text not for what it does, or what it says, but how it makes us feel—the ways in which it “imitates… meaning” but nonetheless “overflows the borders of signification.” Paradoxically, language models operate only because they work to minimize chance in the selection of words—by imposing an obligation on language—and yet we’ve seen their potential to allow writers to speak as though “nothing is compulsory.”
If you go back through the talk, you’ll see that I was very careful to say that language models can only produce poetry. I never said that a language model can produce a poem. Hartman distinguishes between the two in Virtual Muse, saying:
… the program could produce a simplistic kind of poetry forever, but it could never, by itself, produce a poem. All sense of completeness, progress, or implication was strictly a reader’s ingenious doing.27
I like the distinction that Hartman draws here. To tease it out a little bit, Hartman seems to be saying that poetry is a material, which can result from any process (whether conventional composition, free-writing, or tinkering with language models). A poem, on the other hand, is an intentional arrangement resulting from some action: someone decides where the poem begins and ends. A poem, I would say, is the site where “hollow and void” poetry is tactically deployed in a physical and social context, in order to achieve a particular effect. The poem unites poetry with an intention. So yes, a language model can indeed (and can only) write poetry, but only a person can write a poem.
For one example of the kind of coverage GPT-2 was receiving at the time, see: Mak, Aaron. “When Is Technology Too Dangerous to Release to the Public?” Slate Magazine, 22 Feb. 2019, https://slate.com/technology/2019/02/openai-gpt2-text-generating-algorithm-ai-dangerous.html.↩︎
See, for example: Doctorow, Cory. “Some Pretty Impressive Machine-Learning Generated Poetry Courtesy of GPT-2.” Boing Boing, 15 Mar. 2019, https://boingboing.net/2019/03/15/digital-lit.html.↩︎
Böttger, Daniel. “On the Significance of Gwern’s Poem Generator.” Seven Secular Sermons, 12 Mar. 2019, http://sevensecularsermons.org/on-the-significance-of-gwerns-poem-generator/. (my emphasis)↩︎
Parkinson, Hannah Jane. “AI Can Write Just like Me. Brace for the Robot Apocalypse.” The Guardian, 15 Feb. 2019, http://www.theguardian.com/commentisfree/2019/feb/15/ai-write-robot-openai-gpt2-elon-musk.↩︎
Bosker, Bianca. “We’re Ready For Our Robot Poet Overlords.” HuffPost, 19 Apr. 2014, https://www.huffpost.com/entry/robot-poets-pew-poll_n_5175877.↩︎
Translation from Al Filreis’ Modern & Contemporary American Poetry syllabus.↩︎
Tzara’s Dada Manifesto on Feeble Love and Bitter Love. Translation from: http://www.391.org/manifestos/1920-dada-manifesto-feeble-love-bitter-love-tristan-tzara.html↩︎
Hayes, Brian. “Computer recreations.” Scientific American, vol. 249, no. 5, 1983, pp. 18–31. JSTOR, http://www.jstor.org/stable/24969024.↩︎
Kenner, Hugh, and Joseph O’Rourke. “A Travesty Generator for Micros.” BYTE, vol. 9, no. 12, Nov. 1984.↩︎
Strickland, Stephanie, et al. ReRites: Human + A.I. Poetry ; Raw Output : A.I. Trained on Custom Poetry Corpus ; Responses : 8 Essays about Poetry and A.I. Anteism, 2019, p. 171.↩︎
For a good discussion of the dangers and limitations of large pre-trained transformer models, see Bender, Emily M., et al. “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?”Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Association for Computing Machinery, 2021, pp. 610–23. ACM Digital Library, https://doi.org/10.1145/3442188.3445922.↩︎
Radford, Alec, et al. “Language Models Are Unsupervised Multitask Learners.” 2019. https://github.com/openai/gpt-2↩︎
See Brown, Tom B., et al. “Language Models Are Few-Shot Learners.” ArXiv:2005.14165 [Cs], July 2020. arXiv.org, http://arxiv.org/abs/2005.14165.↩︎
Austin, John Langshaw. How to Do Things with Words. Oxford University Press, 1975.↩︎
Ibid., p. 22.↩︎
Ibid., pp. 133–147.↩︎
Williams, William Carlos. Spring and All. Contract Publishing Co., 1923, p. 67.↩︎
Emily Dickinson (L342a, 1870), my emphasis.↩︎
“Large, general language models could have significant societal impacts, and also have many near-term applications […] including the following…: Generate misleading news articles; impersonate others online; automate the production of abusive or faked content […] Due to concerns about large language models being used to generate deceptive, biased, or abusive language at scale, we are only releasing a much smaller version of GPT-2 along with sampling code.” Radford, Alec, et al. “Better Language Models and Their Implications.” OpenAI Blog, 14 Feb. 2019, https://openai.com/blog/better-language-models/.↩︎
Lantz, Frank. “The Immersive Fallacy.” 2005. YouTube, https://www.youtube.com/watch?v=6JzNt1bSk_U.↩︎
Shane, Janelle. “AI AI Weirdness.” AI Weirdness, https://aiweirdness.com/post/626712039215202304/ai-ai-weirdness. Accessed 28 Aug. 2020.↩︎
Hartman, Charles O. Virtual Muse: Experiments in Computer Poetry. Wesleyan University Press, 1996, p. 57.↩︎
LaBelle, Brandon. “Gibberish, Gobbledygook.” Lexicon of the Mouth : Poetics and Politics of Voice and the Oral Imaginary, Bloomsbury Academic & Professional, 2014 (paraphrasing Kristeva in Revolution in Poetic Language)↩︎
Roland Barthes, in Johnson, Kent. “A Fractal Music: Some Notes on Zukofsky’s Flowers.” Upper Limit Music: The Writing of Louis Zukofsky, edited by Mark Scroggins, University of Alabama Press, 1997.↩︎
Hartman, Charles O. Virtual Muse: Experiments in Computer Poetry. Wesleyan University Press, 1996, p. 31 (bold emphasis mine).↩︎